다음 대표적은 오픈소스 PDF to Markdown 변환 도구를 비교해보고,
PDF를 마크다운으로 변환시키는 과정에서 개선할 만한 부분을 알아보려고 한다.
오픈소스 PDF to Markdown 변환 도구 비교
- Marker (datalab): 최근 가장 주목받는 도구로, 딥러닝 모델을 사용하여 ocr을 수행한다.
- surya 라는 ocr 모델을 이용해서 ocr을 수행.
- OCR in 90+ languages that benchmarks favorably vs cloud services
- Line-level text detection in any language
- Layout analysis (table, image, header, etc detection)
- Reading order detection
- Table recognition (detecting rows/columns)
- LaTeX OCR
- ‘SURYA OCR → 초안 → [LLM 이용 수정/보완] → 최종 결과물’ 과정을 거쳐 결과물을 만들어 냄
- surya 라는 ocr 모델을 이용해서 ocr을 수행.
- Docling (IBM): IBM에서 출시한 도구
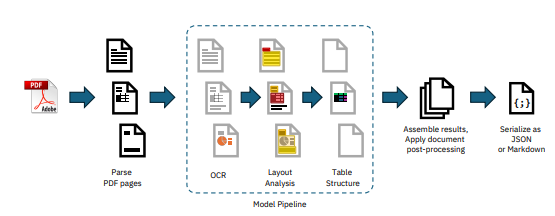
- 위 이미지와 같은 과정을 거쳐 결과물을 만들어 냄. docling technical report
- Parse PDF pages 단계는 docling-parse(open-source a custom-built PDF parser, which is based on the low-level qpdf library. )를 이용해서 파싱 + pypdfium2를 이용해서 페이지 이미지 렌더링
- ocr은 서드파티 이용(surya도 이용할 수 있지만 이용한다면 Text Detection + recognition만 surya 이용됨)
- layout analysis는 자체 모델(RT-DETR를 DocLayNet으로 재학습한 모델)
- table stucture는 자체 모델(table former)
- assembly 과정은 docling-core
변환 과정 알아보기
두 오픈소스에서 PDF를 MD로 변환시키는 과정에서 기본적인 과정은 유사하다.
따라서 위 docling의 경우를 기준으로 설명하면 다음과 같다. (파일을 읽는 부분 ~ 각 부분을 어떻게 판단하고 보정하는지 까지 살펴보면)
parse PDF pages 단계에서는
- pdf 파일을 적절하게 읽어 잘 파싱해내는 부분과 (pdf 파일 읽기에서 언급했듯이)
- pypdfium2를 이용해서 각 요소가 차지하는 영역을 이미지로 만들어 내는 부분이 있다.
OCR 단계에서는
- 각 비트맵들이 차지하는 영역을 전체 페이지 크기와 비교해서
- 너무 크면(ex. 전체 페이지 크기는 100인데, 비트맵 크기가 90) 전체 페이지를 대상으로 OCR
- 너무 작으면(ex. 전체 페이지 크기는 100인데, 비트맵 크기가 1) OCR을 수행하지 않음
Layout Analysis 단계에서는
- 이미지 정보를 이용해 적절하게 각 부분이 어떤 것인지 판단해낸다
- 판단해 낸 부분에 이전 단계에서 얻어낸 정보를 입힌다. + 누락 보정..
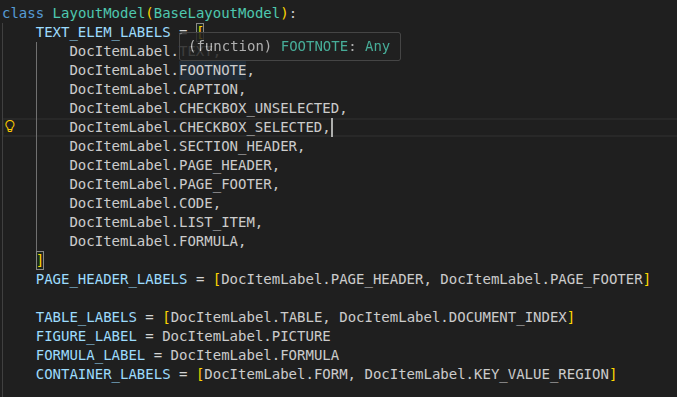
Table Structure 단계에서는
- layout을 table로 판단했다면 수행하고
- 이전 단계들에서 얻은 정보를 이용해서 구조화된 테이블을 예측해낸다.
⇒ 테이블 뿐만 아니라 Layout Analysis 에서의 결과를 바탕으로 보완하는 단계를 둔다.
개선해볼 여지…?
pdf to md 과정에서 테이블과 수식을 잘 변환하지 못하는 문제가 많이 생긴다. 이는 다음과 같은 이유로 추정된다.
PDF object types에서 보았듯이 pdf 파일 자체는 테이블 타입이라던가 수식 타입이 따로 있는 것이 아니다. 따라서 테이블 자체는 렌더링 했을 때 우리 눈에 테이블로 보일 뿐이지, 특정 위치에 특정 텍스트가 쓰인 것으로 판단된다. ← 한번 직접 확인해 볼 필요성이 있음.
따라서 marker나 docling에서도 파싱해낸 텍스트 정보만을 이용하지 않고 pypdfium2와 같은 도구를 이용해 렌더링한 이미지를 이용하는 것이다.
즉 layout모델이 해당 부분을 어떠한 구조적 정보(ex. 테이블, 수식, …)로 판단하면
→ 그 부분의 이미지와 파싱해낸 텍스트 정보, ocr 정보들을 이용해서
⇒개선하는 커스텀 모델 이용 or vlm 이용 or mathpix같은 api 이용
정도가 직관적으로 떠오르는 방법들이다.
그런데 문제는 위 방법들은 이미 marker나 docling과 같은 도구에서 구현되어 있는 것으로 보인다.
marker나 docling 모두 구조적 정보 개선에 이용하는 커스텀 모델이 있고,
+ marker는 llm이용해서 개선하는 옵션이 있다.
정리
pdf 파일 구조 에서 알 수 있듯, pdf는 렌더링을 위한 포멧이다.
따라서파일 자체를 파싱해서 얻어낸 정보(어떤 위치에 어떤 도형/텍스트가 있다)와렌더링한 이미지 정보를 이용한다. (marker/docling 모두 tagged pdf의 Logical Structure 정보를 이용하진 않는 것으로 보인다.)
- mathpix같은 api 이용(marker나 docling엔 없으니 이걸 이용해 보는 방법)
- marker의 ocr 모델 surya(https://github.com/datalab-to/surya/tree/master) 를 파인튜닝 해 보거나
- pdf parser를 개선… (개선할 수 있을까..?) (tagged pdf 정보 이용)
이 정도가 당장 떠오르는 개선 방안 .
pdf 문서가 아니라면 (ex. pptx)
- 해당 문서 → pdf → md 과정을 거치는 것보다
- 해당 문서 → md를 하는게 나을지도 모른다.